Back to The EDiT Journal
GenAI in the Real World: Lessons from Education Deployments
Common failure modes in Retrieval-Augmented Generation systems.

Ammar Mohanna
AI Engineering Lead, EDT&Partners

EDT&Partners


AI in Education
Tech Teams

In this article
The core misconception
Three annonymized client snapshots (EdTech)
RAG failure patterns to watch for (quick checklist)
“When RAG Is Not Enough” (decision tree)
RAG and its relatives: what they try to fix (at a glance)
Cost pressure points (and why they hurt)
Minimal anti-patterns inventory (to recognize early)
Where this leaves us
Appendix: Terms in plain language (for non-technical readers)
At EDT&Partners, our mission is to help education organizations use technology in ways that create real, measurable impact for learners, educators, and institutions. GenAI is now central to that effort, but its success depends on the quality and structure of the information it draws from. Across our work with universities, ministries, and EdTech platforms, one pattern repeats: GenAI initiatives succeed or fail based on the quality and structure of the underlying information. Retrieval-Augmented Generation, or RAG, is meant to help address this, yet in the education sector it often breaks in consistent and avoidable ways.
RAG looks simple on slides: drop your documents into an embedding model, store vectors, and let a large model answer questions with citations. In practice, especially in EdTech where content is messy, multilingual, and highly contextual, RAG fails in predictable ways.
Why this matters for the education sector
This article connects the technical details of RAG with the real-world complexities of educational content. It is a problem catalog based on our work with education clients, written for EdTech executives and developers. We name AWS services that we regularly use (e.g., Amazon Bedrock, Amazon OpenSearch Service, Amazon S3, Amazon Textract), include anonymized client snapshots, propose block-diagram visuals/wireframes, and end with a comparison table of RAG variants and a decision tree titled “When RAG Is Not Enough”.
The challenges described here influence trust, governance, accessibility, and student experience. In other words, they shape whether GenAI delivers meaningful value or becomes another overhyped tool.
The core misconception
“If we embed the documents, the system will ‘understand’ them like a human”.
It won’t. RAG is only as good as:
- how text is extracted (OCR, layout)
- how it’s chunked (units of meaning)
- how context is preserved (references, figures, URLs)
- how retrieval is biased (language, term frequency, domain)
- how costs shape design tradeoffs (what you actually index vs. what you can afford)
Below are the recurring failure modes we see in EdTech environments.
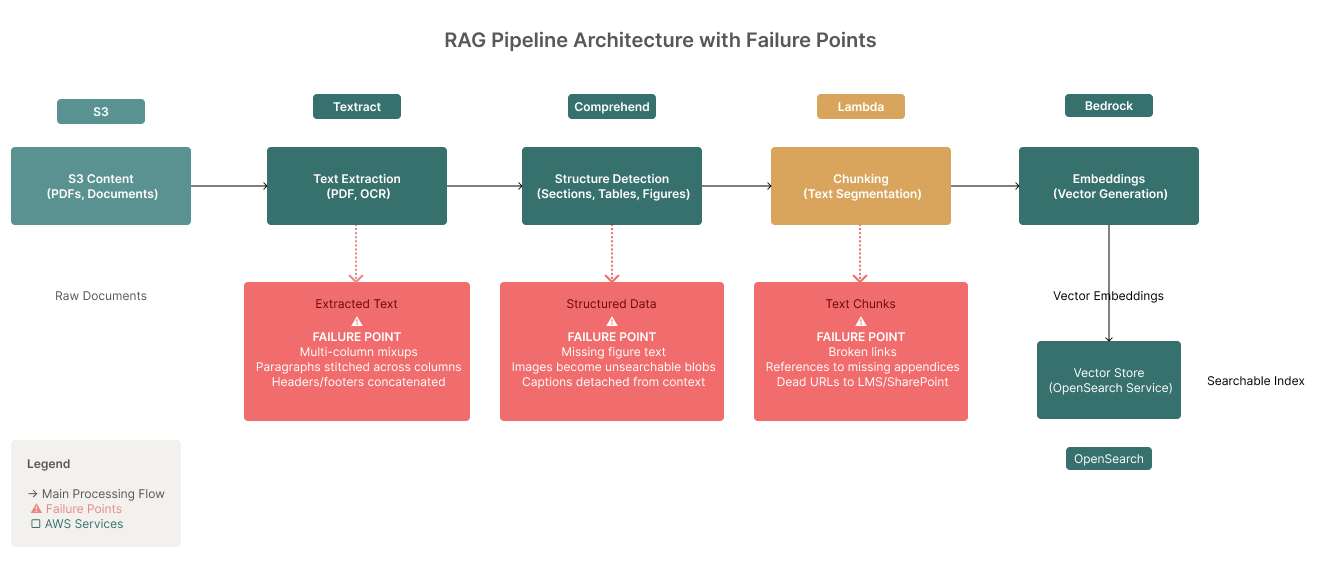
1) Documents are messy by default
What we see
- Multi-column PDFs, sidebars, footnotes, headers/footers that get concatenated into nonsense.
- “Scanned PDFs” of policies, accreditation packets, or historical syllabi with poor OCR.
- Broken cross-references: “See Table 3 in Appendix B” with no Appendix captured; links to LMS pages or SharePoint files that are private, moved, or 404.
- Course materials split across LMS, departmental drives, email attachments, and cloud disks; same file in six versions.
How it breaks RAG
- Garbage chunks: paragraphs stitched across columns, captions glued to footnotes, tables turned into word salad.
- Lost grounding: the chunk that looks relevant lacks the surrounding sentence that actually defines a term or exception.
- Dead trails: the retrieved chunk points to a resource that the system can’t reach or no longer exists.
EdTech examples
- Policy Q&A: the “late submissions” rule is retrieved without the special exception for lab sections because the exception sits in a table caption missed by the extractor.
- Accreditation binder: screenshots of KPIs embedded in a PDF become images with no text, retrieval never finds them.
- Program handbook: “refer to Appendix C” is retrieved as an answer, but Appendix C wasn’t ingested.
2) Language and retrieval bias
What we see
- Mixed-language repositories (e.g., English and Spanish versions of student services policies; bilingual course materials).
- Queries in one language, but the “best” answer lives in another language version.
- Embedding models (and downstream rankers) that favor English for frequency/coverage reasons.
How it breaks RAG
- Language bias: when both an English and Spanish chunk match, retrieval leans to English even if the Spanish version is more up to date or contextually complete.
- Hybrid queries: user asks in English about a concept that’s defined with loanwords or terms of art in another language; retrieval picks the wrong term family.
EdTech examples
- Student affairs: an English query about financial aid returns the old English policy rather than the current Spanish version published last month.
- Research repository: bilingual abstracts compete; the English abstract is retrieved, but the critical methods section exists only in the other language.

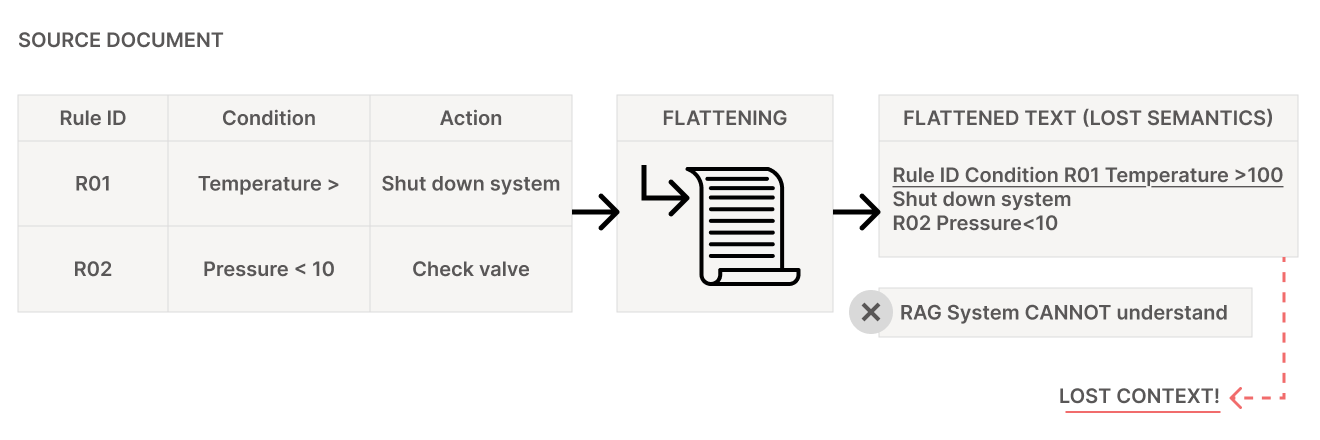
3) Visuals aren’t “just text”: tables, diagrams, schematics
What we see
- Tables encoding rules (“If GPA < 2.0 and credits > 12, then probation”).
- Diagrams expressing flows (appeals, degree audit paths).
- Schematics and plots in research/teaching materials.
- Embeddings that treat flattened tables as token streams—losing row/column semantics.
How it breaks RAG
- Table flattening: columns get linearized; row relationships vanish; numeric constraints lose alignment.
- Figure invisibility: images/plots are ignored or become unsearchable blobs without captions/alt text.
- Context drift: a diagram is retrieved, but detached from the explanatory text that disambiguates it.
EdTech examples
- Degree audit table: retrieval surfaces “students on probation must…” but misses the exception in a footnoted column.
- Lab safety schematic: answer cites a diagram filename without extracting the steps encoded in the figure.
- Assessment rubric: column headers like “Exceeds/Meets/Below” become repeated tokens; the mapping to criteria is lost.
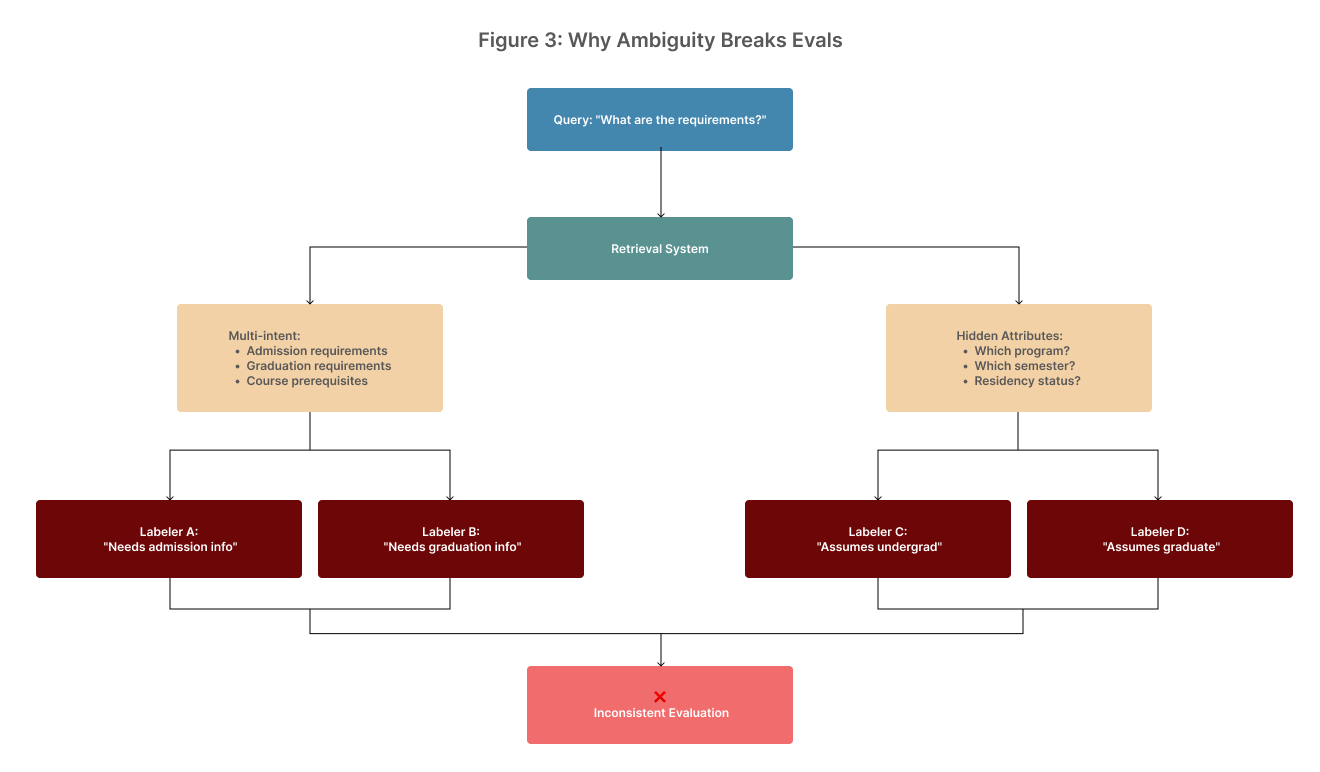
4) Evals are unclear because questions are unclear
What we see
- Stakeholders judge “how good RAG is” using open-ended, ambiguous, or multi-intent queries: “What are the requirements?” “How do I appeal?”
- Labelers (often SMEs) disagree on what constitutes a “good” answer without a shared rubric or golden references.
- Evaluation conversations drift into “I know the correct answer” anecdotes that aren’t in the corpus.
How it breaks RAG
- No stable target: we can’t measure retrieval quality if we don’t fix what “relevant” means for a scenario.
- Moving ground truth: policies change mid-eval; corpora are refreshed without versioning; labels go stale.
- Hidden context: SMEs answer from memory or external sites not available to the system.
EdTech examples
- Admissions FAQ: “What are the requirements?”—the correct answer depends on program, residency, and term. Retrieval is penalized for not guessing hidden attributes.
- Exam policy: labelers disagree whether an answer citing last year’s PDF should be “acceptable” because “nothing changed.”
Note: We are not proposing eval solutions here; only highlighting why RAG gets graded unfairly or inconsistently in the wild.
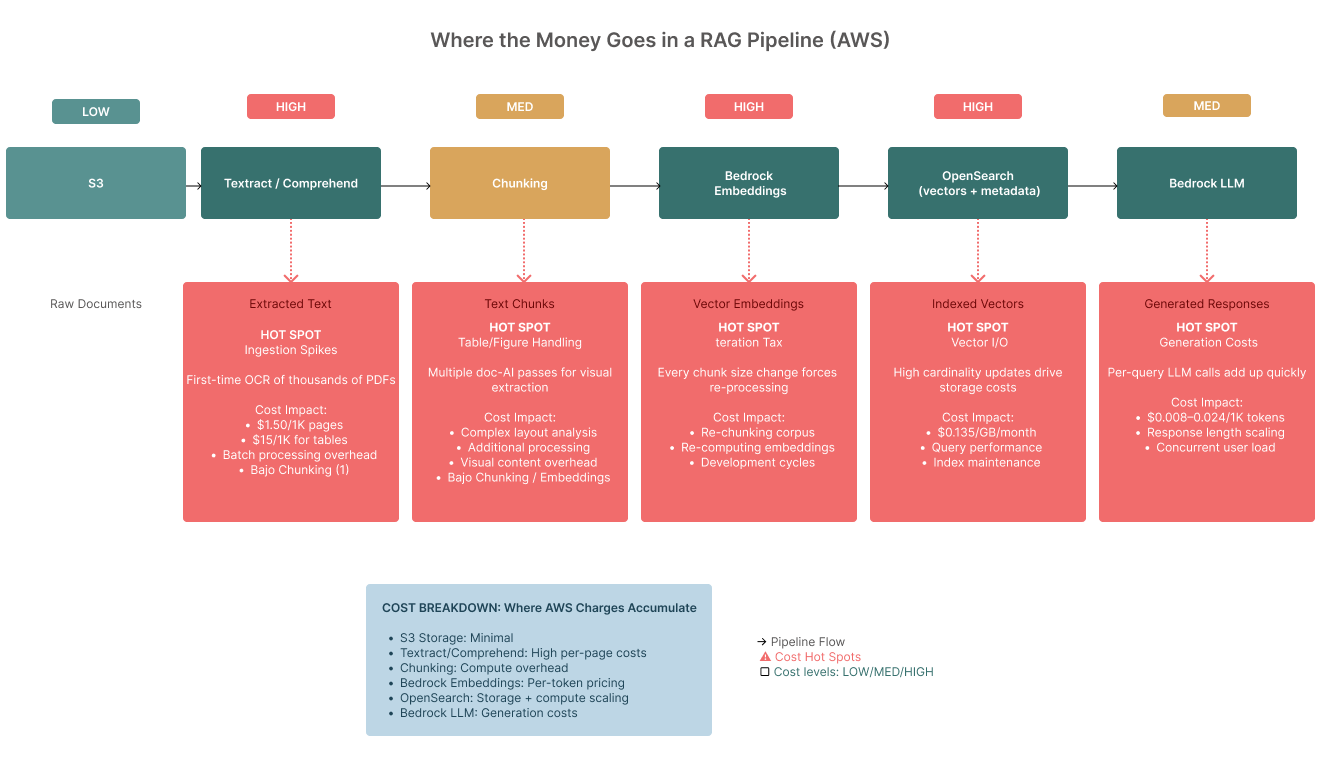
5) Cost is a design constraint (not an afterthought)
Where costs appear (AWS-centric)
- Content prep: Amazon Textract (OCR), Amazon Comprehend (entity/key-phrase extraction), layout analysis steps.
- Storage and indexing: Amazon S3 for raw/processed files; Amazon OpenSearch Service for vectors/metadata.
- Embeddings & generation: Amazon Bedrock for embedding and LLM calls.
- Glue & orchestration: AWS Glue/AWS Lambda/AWS Step Functions moving documents through pipelines.
- Evals and refreshes: repeated embedding and indexing when content changes; re-running test suites.
Why this surprises teams
- Ingestion spikes: first-time OCR and embedding of thousands of PDFs is expensive.
- Table/figure handling: extracting, captioning, and enriching visuals adds doc-AI passes.
- Vector I/O: high cardinality and frequent updates drive OpenSearch storage and query costs.
- Iteration tax: every “small tweak” to chunking/filters can force re-processing and re-indexing.
Three annonymized client snapshots (EdTech)
1. University A — Policy/Handbook Q&A
Problem: Students ask policy questions; staff overwhelmed. Content: PDFs with multi-column layouts, footnotes, and tables.
What went wrong: Extraction flattened tables; “special cases” existed only in footnotes; retrieval returned incomplete rules.
What helped (directionally): Better structure capture for tables/footnotes, more careful chunk boundaries, and emphasizing nearby definitions. (Details in our next post.)
2. Online Program B — Course Ops & Syllabus Search
Problem: Instructors and TAs search syllabi for make-up exam policies; same course has multiple versions across semesters.
What went wrong: Retrieval pulled outdated versions (most frequently accessed, not most recent); cross-links to LMS pages were dead.
What helped (directionally): Version awareness and link validation during ingestion; stronger recency/context signals at retrieval time.
3. College C — Accreditation Evidence Binder
Problem: Rapid turnaround for an external review. Evidence mixed across PDFs with embedded images of charts.
What went wrong: OCR missed text embedded in figures; citations pointed to figures without the surrounding interpretive text; evaluators flagged “ungrounded” answers.
What helped (directionally): Additional OCR passes for figures, explicit pairing of figures with their captions and explanatory paragraphs.
RAG failure patterns to watch for (quick checklist)
❑ Layout loss: multi-column or table structures turned into flat text.
❑ Orphaned references: “See Appendix/Table/Figure” with no accessible target.
❑ Language bias: equally relevant bilingual chunks—English dominates.
❑ Figure invisibility: diagrams/plots never retrievable by concept.
❑ Version drift: correct answer exists, but retrieval picks an older doc.
❑ Ambiguous queries: evals penalize retrieval for missing hidden parameters.
❑ Cost creep: doc-AI passes and re-index cycles dominate the budget.
❑ No provenance: returned chunks lack clear source, timestamp, or version tag.
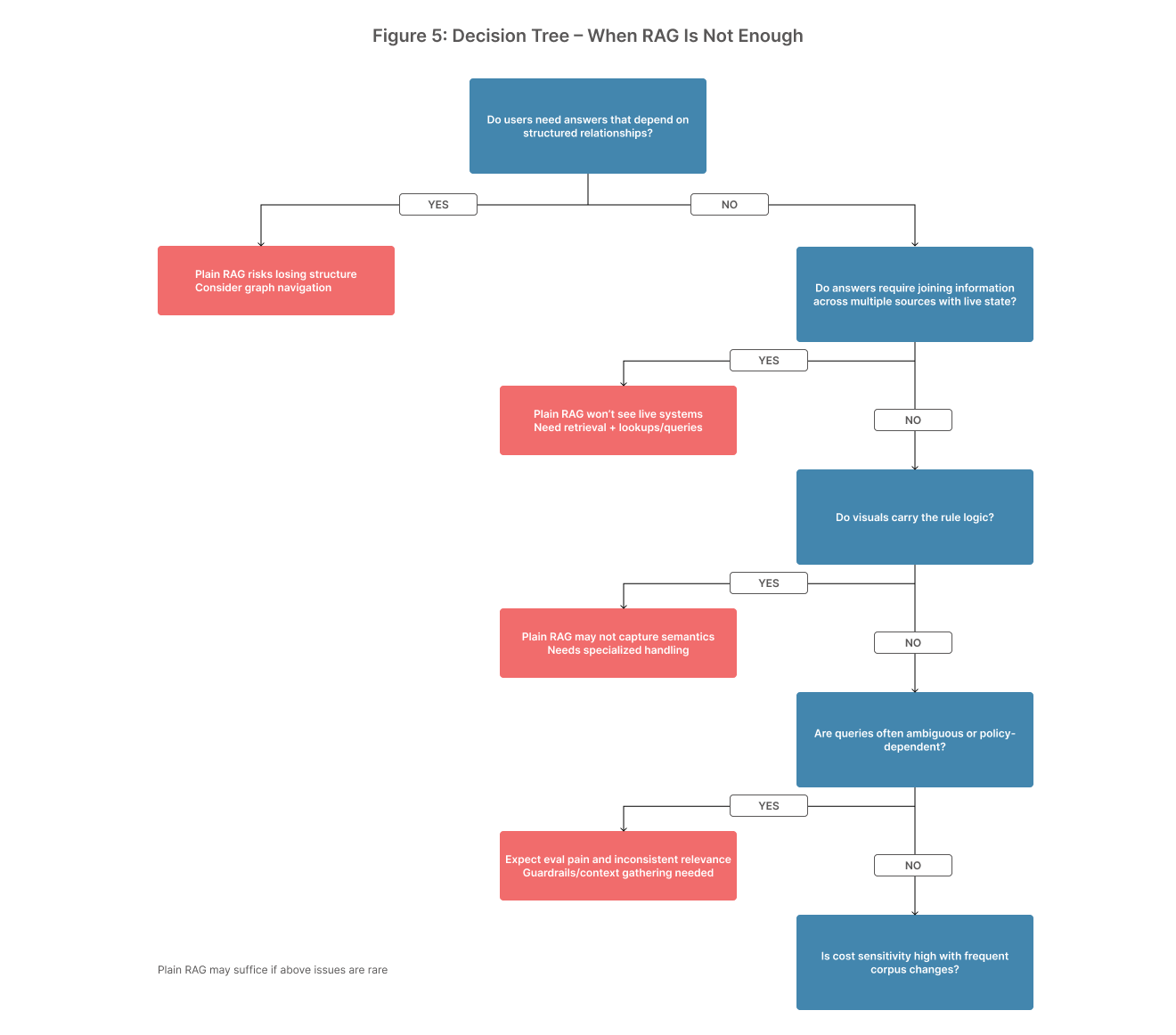
“When RAG Is Not Enough” (decision tree)
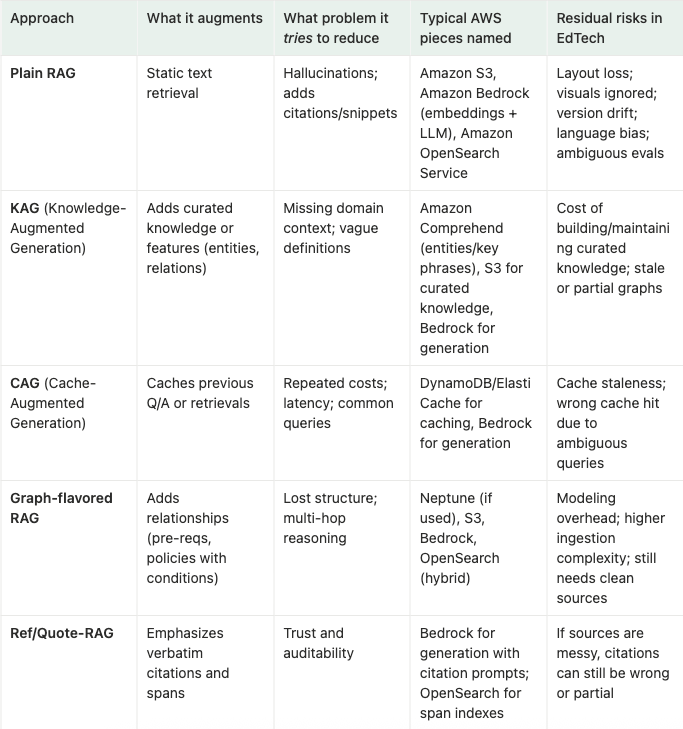
RAG and its relatives: what they try to fix (at a glance)
Note: This table names patterns and intent. We’ll discuss approaches in the next article.
Cost pressure points (and why they hurt)
- OCR & layout intelligence: Scanned handbooks and accreditation binders can require multiple Amazon Textract passes (tables, forms), plus post-processing in AWS Glue/Lambda. Each pass costs money and time—and re-runs multiply costs during iteration.
- Embedding scale: High-granularity chunks inflate index size in Amazon OpenSearch Service; frequent updates (new terms, rolling syllabi) re-compute embeddings in Amazon Bedrock.
- Visual treatment: Extracting tables/figures into searchable artifacts adds processing and storage.
- Evaluation cycles: Even basic offline checks require running many retrievals repeatedly; with changing corpora, you pay this tax often.
- Operational overhead: Every small adjustment (chunk size, metadata schema, filters) may trigger re-indexing—multiplying previous costs.
We’ll discuss cost controls and design tradeoffs next time; the key point here is that costs are architectural. Treat them as first-class requirements.
Minimal anti-patterns inventory (to recognize early)
- “PDF in, magic out.” No explicit plan for OCR quality, multi-column parsing, or table extraction.
- “All chunks are equal.” No versioning or freshness signals; top-k is purely vector similarity.
- “Language will sort itself out.” No language or locale awareness in retrieval.
- “Figures don’t matter.” No pipeline for tables/diagrams; assumes embeddings will “see” them.
- “Let’s just test with random questions.” No scenario-grounded queries; no fixed reference answers.
- “We’ll optimize cost later.” Ingestion and iteration costs spike, creating pressure to cut corners where it matters most.
Where this leaves us
RAG is valuable, but not magical. In education settings, source quality, structure, and context dominate outcomes. When teams simply embed whatever they can crawl, they'll often create systems that appears to work in demos yet fails on the edge cases that students, faculty, and accreditation reviewers care about.
Understanding these failure modes is the first step toward building GenAI systems that are reliable, transparent, and aligned with real educational needs. Our follow-up post will share practical approaches for addressing each issue, including how we use AWS tools and retrieval-aware agents to navigate structured content rather than treating knowledge as flat text.
Watch for the follow-up article where we share the approaches we’ve found effective on AWS to mitigate these exact problems.
Appendix: Terms in plain language (for non-technical readers)
- RAG (Retrieval-Augmented Generation): a pattern where an LLM reads snippets from your documents and uses them to answer questions, ideally with citations.
- Embedding: turning text into numbers so similar meanings are close together; used to find relevant chunks.
- Chunking: splitting documents into pieces (paragraphs, sections) to index them separately.
- OCR: converting images of text (scans, photos) into machine-readable text.
- Citation/grounding: showing where the answer came from.
- Vector store: a database that can search by meaning (similarity), e.g., Amazon OpenSearch Service with vector capabilities.
Ammar Mohanna
AI Engineering Lead, EDT&Partners
An AI consultant and engineering leader, Ammar is passionate about building ethical and accessible AI, specializing in graph learning, prompt engineering, and real-time systems.
EDT&Partners
The EDT&Partners Editorial Team brings together education and technology experts sharing insights, stories, and strategies shaping the future of learning.
Join our newsletter
Be part of our global community — receive the latest articles, perspectives, and resources from The EDiT Journal.
.png)

.png)
