Back to The EDiT Journal
Agentic AI Won’t Fix a Broken Workflow; A Lean, Measured Process Will
Navigating the vast AWS ecosystem can be challenging. How can you accelerate your cloud journey, reduce risks, and achieve better outcomes?

Ammar Mohanna
AI Engineering Lead, EDT&Partners


AI in Education
Cloud & Infrastructure
EdTech
Publishers

In this article
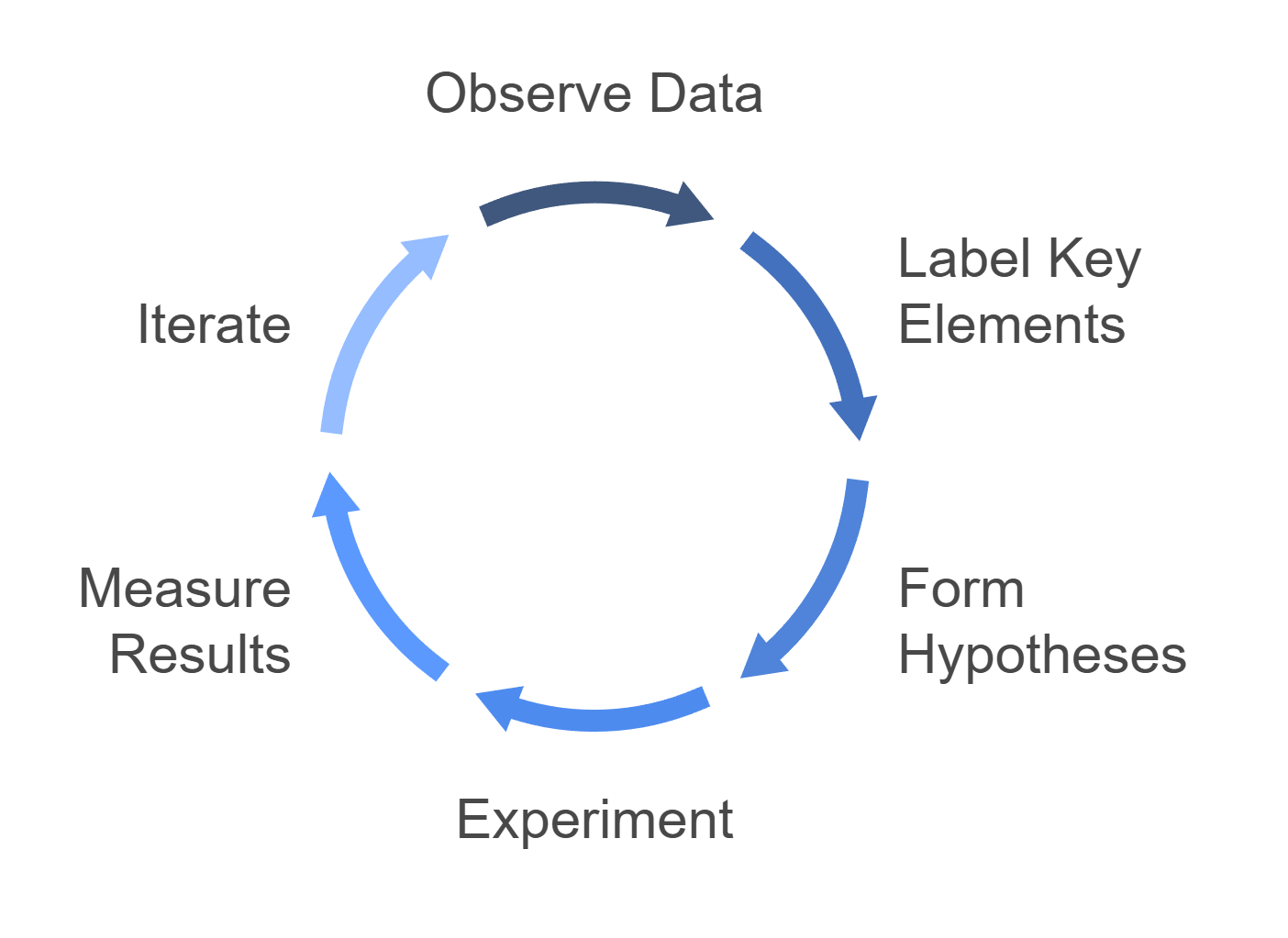
1. Start with Observation – Look at the Data
2. Label What Matters
3. Form Hypotheses, Not Hunches
4. Experiment Like a Scientist
5. Measure, Don’t Vibe-Check
6. Close the Loop – Iterate Relentlessly
7. Eval-Driven Development for Agents
8. The Takeaway
9. Automated Evaluators Amplify, They Don’t Replace, Humans
Agentic AI is the hot new buzzword. Teams hope that dropping a “self-driving” agent into their stack will magically cure every product pain point; just like some once believed an LLM-as-judge would. It won’t. An agent is only as good as the workflow that surrounds it.
In education, where EDT&Partners helps institutions, ministries, and EdTech companies design AI systems that actually improve learning, this is especially true. Building effective agentic systems means grounding them in real student and educator interactions, aligning with pedagogical goals, and instrumenting every loop for measurable progress. Rigorous evaluation, tight feedback loops, and disciplined iteration still run the show. Below is a clearer, step-by-step path, written in my plain-spoken style, showing how to build and improve agentic systems without chasing shiny tool.
1. Start with Observation – Look at the Data
Agentic AI lives on signals. Before spinning up planners, retrievers, or tool executors, spend time with real traffic. Examine the raw user prompts, the intermediate thoughts, the final answers, and the traces of tool calls. Then review how users react—where they click, when they correct the agent, and whether they give a thumbs-up or thumbs-down. Patterns of success and failure jump out once the data is on the table, and those failure modes become your to-do list.
2. Label What Matters
You don’t need a mountain of labels; you need a balanced slice that captures the pain points uncovered in the first step. Aim for a representative set with an even split of passes and fails across the full range of inputs. These ground-truth annotations become the backbone of every evaluation you run from this point forward.
3. Form Hypotheses, Not Hunches
Next, articulate why the agent stumbles. Perhaps retrieval returns irrelevant material, the planner drifts in circles, or a tool integration supplies stale data. Writing each theory down forces clarity and sets up focused experiments rather than vague tinkering.
4. Experiment Like a Scientist
Treat every tweak, whether it’s a prompt rewrite, a new search index, or a different model, as a controlled A/B test. Define the metric before you start, hold a baseline for comparison, and only ship the change if it outperforms the control on the metric that truly matters.
5. Measure, Don’t Vibe-Check
Agentic stacks are noisy, and gut feelings won’t cut it. Capture hard numbers: track accuracy, recall, latency, or defect rate per hundred calls; log pairwise win-rates against the baseline; and monitor user engagement deltas. If you can’t quantify the lift, you cannot claim progress.
6. Close the Loop – Iterate Relentlessly
When an experiment succeeds, promote the change with confidence. When it falls short, dive into the error logs, refine the hypothesis, and try again. This data flywheel compounds quality and deepens user trust with every turn.
7. Eval-Driven Development for Agents
Think of Evaluation-Driven Development (EDD) as test-driven development for AI. Instead of writing code to satisfy tests, you write an evaluation suite first, then build the agent to satisfy that suite. A baseline prompt gives you day-one numbers; afterward, every planner update, tool integration, or guardrail addition reruns the same evaluations. Instant feedback keeps everyone honest and ensures measurable progress instead of guesswork.

First, write some evals; then, build systems that pass those evals
8. The Takeaway
Agentic AI may feel like magic, yet the magic fades without a data-first mindset, targeted labeling, hypothesis-driven experiments, clear metrics, and relentless iteration. Skip that process, and no autonomous agent, or next-gen evaluator, will rescue your product. Nail the workflow, and the agents will simply make it fly.
9. Automated Evaluators Amplify, They Don’t Replace, Humans
LLM graders, rule engines, and self-critique loops help you watch thousands of interactions without human eyes on every line, but they still require calibration. Continue sampling live traffic, annotate fresh data, and use those labels to align automated judges with real human expectations. Once aligned, the automated layer keeps watch around the clock while you sleep, and you revisit the alignment whenever behavior drifts.
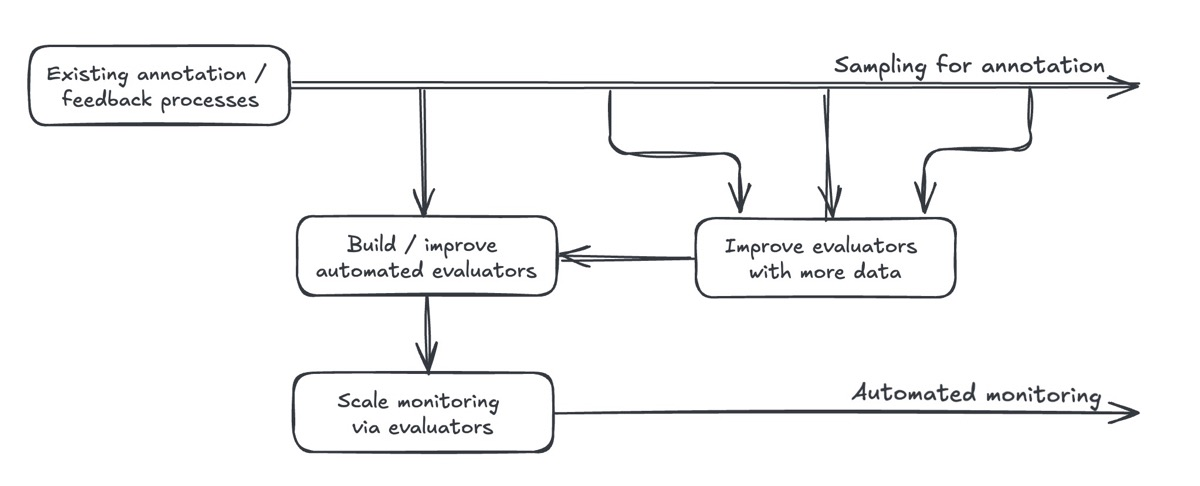
Automated evaluators amplify our existing annotation and feedback processes.
Kick-the-Tires in 90 Seconds: One-Cell Bedrock Evaluation Lab (Colab)
Concepts are nice, but nothing beats running the loop yourself. Paste the cell below into a fresh Google Colab notebook. The script will:
- Prompt you (privately) for an AWS access-key pair and region.
- Send three sample prompts to your agent under test on Amazon Bedrock.
- Ask another Bedrock model to grade the answers 0-1.
- Print a mini-report with accuracy & latency—mirroring the “Measure, Don’t Vibe-Check” mantra from the article.
# 🟢 ONE CELL — copy into Colab and run
!pip -q install boto3 --upgrade
import os, json, time, boto3, statistics, textwrap, getpass
# ─── CREDENTIALS (hidden prompts keep keys out of notebook text) ──────────
os.environ["AWS_ACCESS_KEY_ID"] = getpass.getpass("AWS access key ID: ")
os.environ["AWS_SECRET_ACCESS_KEY"] = getpass.getpass("AWS secret access key: ")
# ─── CONFIG — tweak as needed ────────────────────────────────────────────
REGION = "us-east-1" # or "eu-central-1"
AGENT_MODEL = "anthropic.claude-3-sonnet-20240229-v1:0" # Nova: "cohere.command-r-plus-v1"
JUDGE_MODEL = AGENT_MODEL # can be different
DATASET = [
{"prompt": "Translate to French: 'How are you?'",
"reference": "Comment ça va ?"},
{"prompt": "Summarise: 'AWS released Bedrock, its managed Gen-AI service.'",
"reference": "AWS launched Bedrock, a managed Gen-AI service."},
{"prompt": "Give me three risks of Gen-AI in finance.",
"reference": "Model bias, data leakage, hallucination."}
]
# ─── BEDROCK CLIENT ──────────────────────────────────────────────────────
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
def call_bedrock(model_id: str, prompt: str, temperature=0):
"""Minimal Bedrock invocation for Anthropic or similar chat models."""
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 512,
"temperature": temperature,
"messages": [{"role": "user", "content": prompt}]
}
response = bedrock.invoke_model(
modelId = model_id,
body = json.dumps(body),
contentType = "application/json",
accept = "application/json"
)
return json.loads(response["body"].read())["content"][0]["text"]
def grade(prompt, reference, answer):
rubric = textwrap.dedent(f"""
You are an impartial grader.
Score the ANSWER from 0 (wrong) to 1 (perfect). Respond only with the number.
PROMPT: {prompt}
EXPECTED: {reference}
ANSWER: {answer}
""")
return float(call_bedrock(JUDGE_MODEL, rubric))
# ─── MAIN LOOP ───────────────────────────────────────────────────────────
results = []
for item in DATASET:
t0 = time.time()
answer = call_bedrock(AGENT_MODEL, item["prompt"])
latency = round(time.time() - t0, 2)
score = grade(item["prompt"], item["reference"], answer)
results.append({**item, "answer": answer, "score": score, "latency_s": latency})
print(json.dumps(results, indent=2, ensure_ascii=False))
print("\nAvg-score:",
round(statistics.mean(r["score"] for r in results), 2),
"| Avg-latency:",
round(statistics.mean(r["latency_s"] for r in results), 2), "s")
What just happened?
Stage - Where it maps in the article
Observation - Prompts & references live in the DATASET list.
Experiment - AGENT_MODEL answered live via bedrock.invoke_model().
MeasurementJUDGE_MODEL graded each answer 0-1.
Iteration- Swap models, extend DATASET, rerun—the feedback loop takes seconds.
That’s it—no servers to spin up, just insight.
Ship a new prompt-engineering trick or fine-tuned model? Change AGENT_MODEL, rerun the cell, and let the numbers decide whether it’s hype or progress.
Ammar Mohanna
AI Engineering Lead, EDT&Partners
An AI consultant and engineering leader, Ammar is passionate about building ethical and accessible AI, specializing in graph learning, prompt engineering, and real-time systems.
Join our newsletter
Be part of our global community — receive the latest articles, perspectives, and resources from The EDiT Journal.
.png)
.png)
.png)
